
DSPy: The most misunderstood ̶a̶g̶e̶n̶t̶ ̶f̶r̶a̶m̶e̶w̶o̶r̶k̶ compiler
Other frameworks failed. DSPy has the right abstraction to enable short, clean, code with fast iteration

DSPy.ai is the most misunderstood agent framework. A common articulation of DSPy is that it is a “prompt optimisation agent framework”, but I believe this misses the forest for the trees.
Better slogan: “DSPy: The LLM Compiler for Shortest Cleanest Code”
Paralleling what compilers did to assembly code in the 1940s, abstracting away the assembly code to focus on high-level languages. DSPy abstracts away 100-line prompt boilerplates to focus on the agent logic. DSPy is a powerful abstraction that enables fast iteration, short code, and improves LLM performance with 1-line changes.
Need more convincing? Tobi Lutke, a hardcore coder and CEO of Shopify ($200B+ Co), said: “Both DSPy and (especially) GEPA are currently severely under hyped in the AI context engineering world”.
In this post, we’ll cover how:
DSPy
optimises promptsgives you shorter code (+ PoC)DSPy enables 1-line perf. boost with
dspy.ModuleDSPy prevents LLM lock-in
Are you a TS/JS stack evangelist? Don’t worry, there is a TS/JS implementation of the DSPy abstraction philosophy in ax-llm, and so this post will still be worthwhile to understand other agent frameworks vs DSPy-style abstraction.

Motivation: Agent Frameworks Suck
My motivation for this post was born from a painful 2024 experience: developing a serious codebase with LangChain. After taking the ‘AI influencer propaganda’ bait, 3 weeks were wasted ripping it all out - a sentiment that is not uncommon.
Examples of anti-agent framework hate posts: post 1 | post 2 | post 3

So what’s different about DSPy? They use the right abstraction to solve a lot of the problems that other agent frameworks failed to capture. They genuinely simplify the code, and as a side effect, reduce the number of lines of code. They make LLMs “programmable”, not just on the prompt-level, but on the “multi-agent communication”-level.
DSPy’s abstraction optimises prompts gives you the shortest, cleanest code (+ PoC)
DSPy’s main advantage is clean, short, portable code that focuses on agent logic instead of prompt boilerplate. Translated into engineering benefits, it gives you faster iteration and faster code review. Not the common narrative around DSPy, of auto-prompt optimisation.
To give a proof of concept and empirical results, below is an example comparison of 3 implementations of the 2022-2023 era ChatGPT with DSPy, openai-agents and langchain, trying to write the shortest possible implementation for each, with a lot of Cursor/Claude Code iteration (w/ formatter to limit max line length to 88. See source code for details). For example, a simple Question-Answer response without any web usage in DSPy will be:
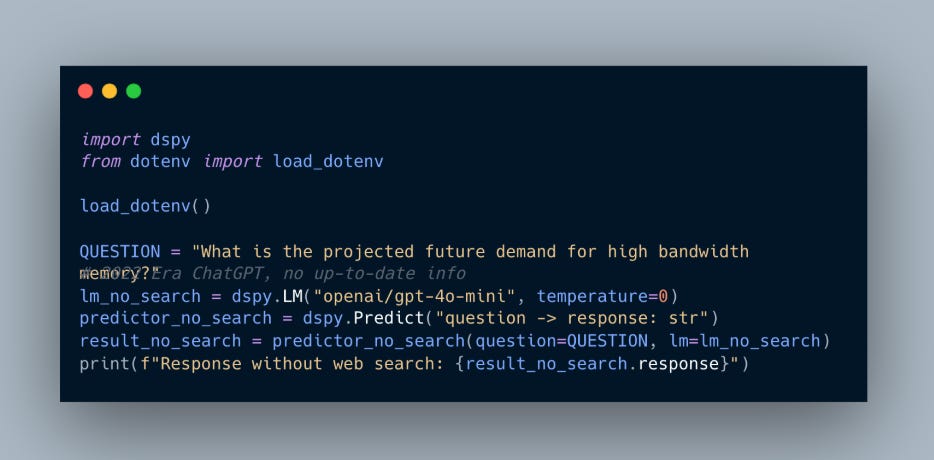
Notice the incredibly succinct implementation with the signature question -> response: str. DSPy then, under the hood, “compiles” these DSPy signatures into prompts that are fed into the LLM. Unlike other frameworks that demand annoying text insertions and extractions (especially with multiple inputs/outputs), DSPy signatures define LLM inputs and outputs declaratively and make input/output parsing easy. DSPy handles the prompting, formatting, parsing, and extraction.
For a slightly more complicated example, we may find examples like the following, with multiple inputs & outputs. (shortened)
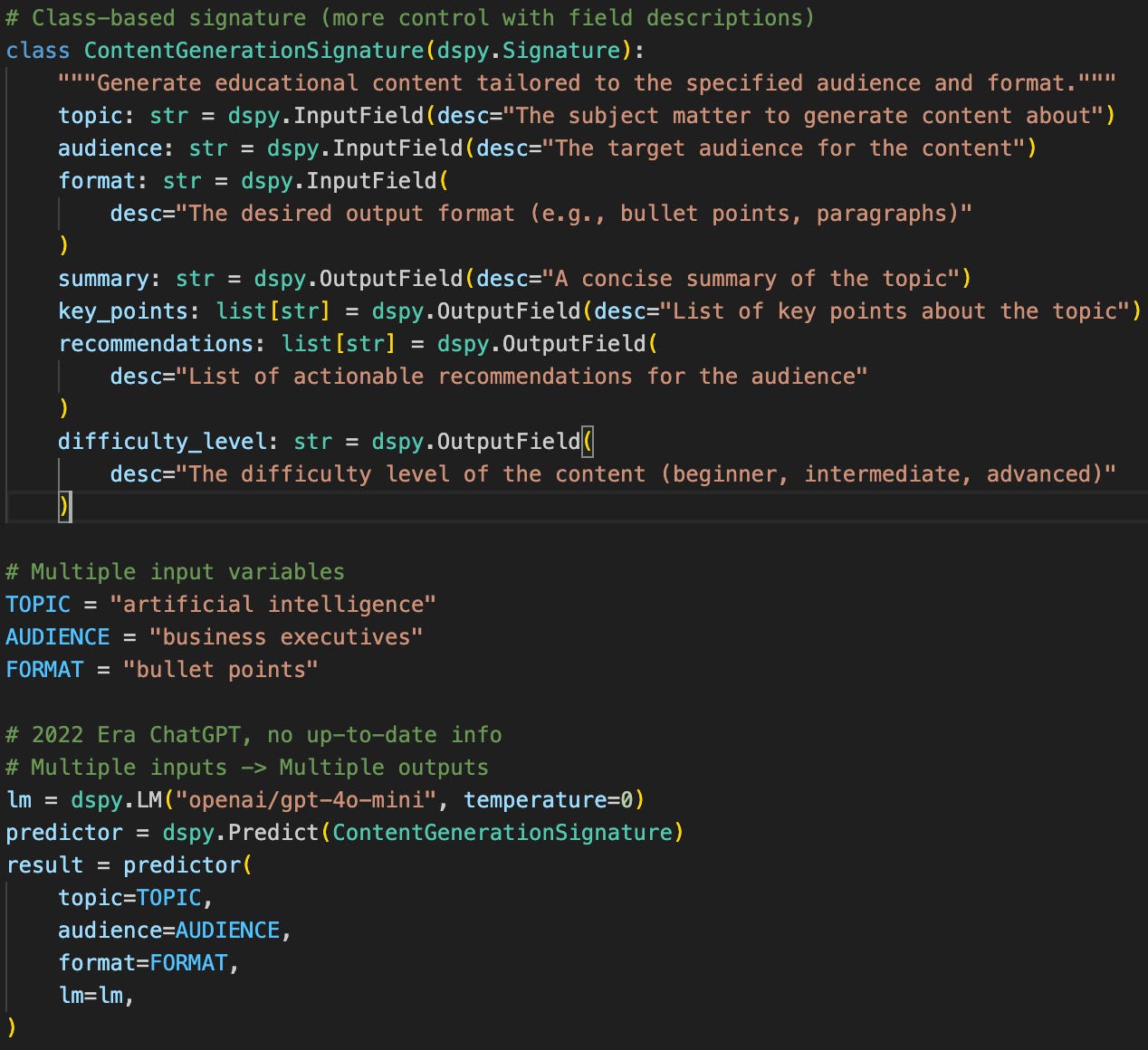
Where are the LLM prompts? Under the hood, DSPy does all the prompt boilerplate formatting of the system prompts and user prompts, so you don’t need to manage any large amounts of text in the code or template files, and you can focus on just the variables and input/output logic.
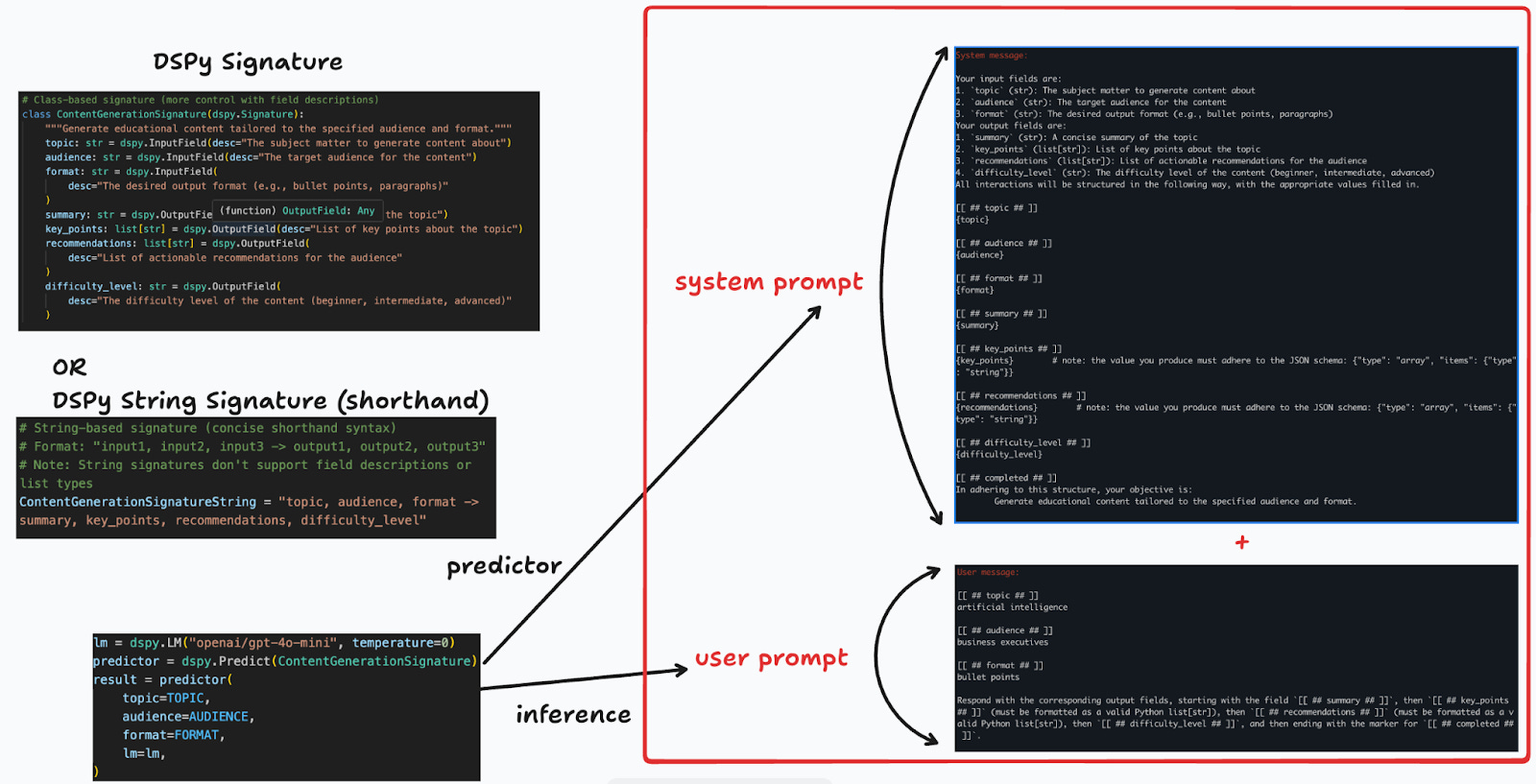
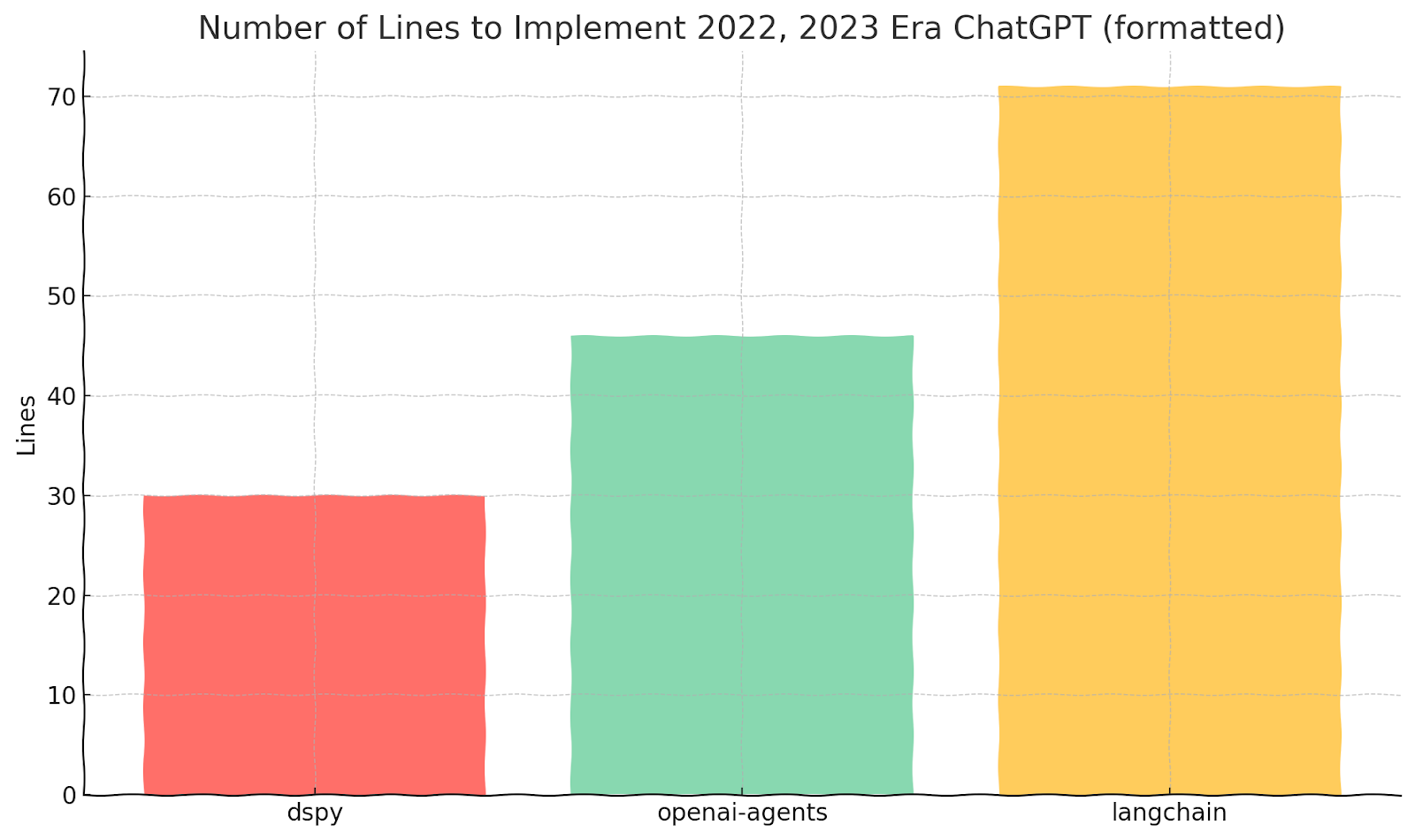
These DSPy signatures enable much shorter code as a result. As a simple comparison, let’s compare the ChatGPT 2022-2023 implementation with the first example using the simple DSPy signature. A minimal number of lines of code (LOC) recreation of this in LangChain takes 2x as many lines.
The LOC comparison is as follows:
Framework | LOC
DSPy: 30
OpenAI Agents: 46
LangChain: 71
See github gist source code to view the actual code.

This succinctness is the first sign of the high–level abstraction DSPy provides, much like a compiler abstracting away low-level assembly with high-level languages (e.g. C++).
As another example, Drew Breunig has done an excellent talk: Let the Model Write the Prompt, where he covers OpenAI’s GPT-4.1 Prompting Guide, showing how over half of the many paragraphs of prompts for GPT-4.1 can be collapsed into a few lines with DSPy, enabling the developer to focus on the detailed context & instructions without worrying about other details.
This will be a recurring theme, where DSPy enables the developer to think about high-level operations and logical flow, rather than being bogged down in the details of the prompts.

DSPy enables 1-line perf. boost with dspy.Module
DSPy’s next superpower is in the 1-line performance improvements with pre-packaged inference strategies through dspy.Module. Short, clean, modular and reusable code that improves LLM orchestration without much effort.
An inference strategy is just a strategy for how different LLM calls work together to get a result to improve the performance of an LLM system. An example of an inference strategy is sampling multiple parallel chains of thought of LLMs and synthesising them all to deliver the best answer. Many inference strategies improving LLM orchestration have been constructed across the field, but their implementation in code is fragmented, leading to developers re-implementing the inference strategies in different codebases. (For examples of other inference strategies, see Anthropic’s Building Effective Agents post, alongside other techniques like Best-of-N, Self-Reflection, Tree of Thoughts, etc.)
Developers needing to re-implement these inference strategies add development time and friction, slowing iteration speed and experimentation.
However! DSPy identifies that all these inference strategies share the same structural property: they map INPUT -> OUTPUT, with some LLM computation in the middle. (As seen in the diagram below)
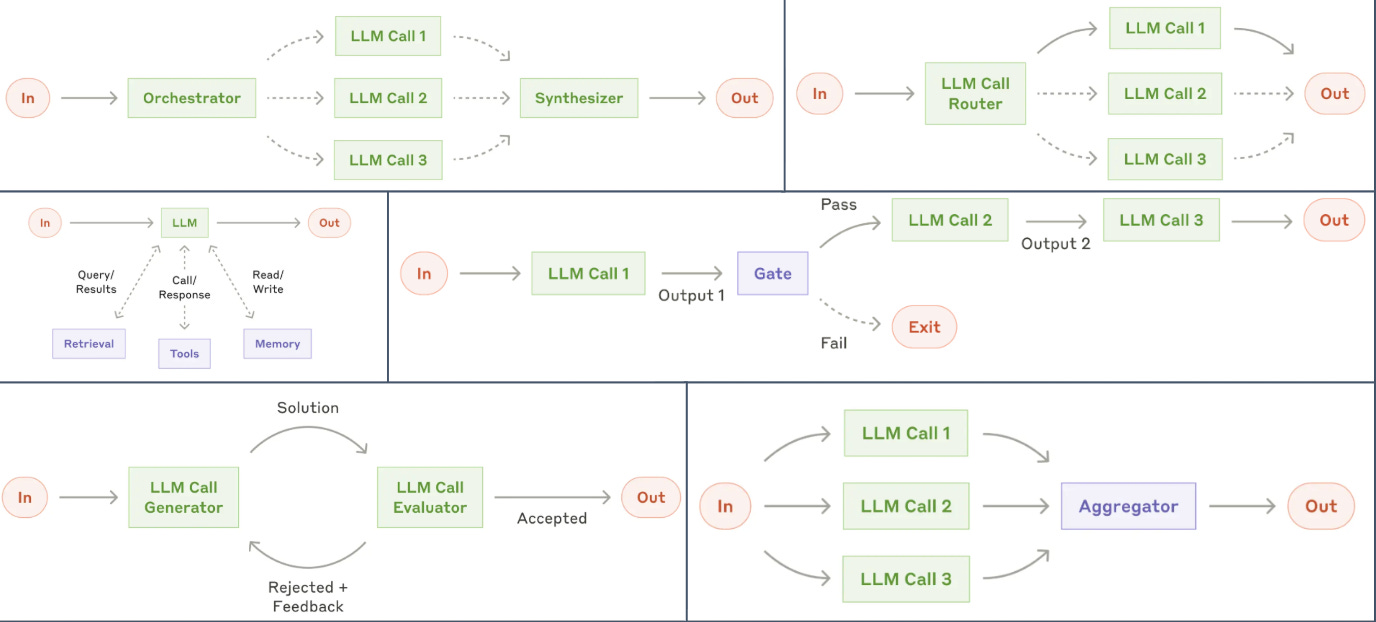
DSPy captures this structural similarity and abstracts these LLM inference strategies into modular, programmable, and reusable modules. This abstraction means developers can experiment with different inference strategies with simple 1-line changes to debug LLM pipelines and improve performance. Much faster than re-implementing every inference strategy.
Example: Say you have a DSPy signature called ExtractEvents that pulls structured data from text. Then, you can simply switch out the middleware inference strategy like this:
dspy.Predict(ExtractEvents) # Basic prediction
dspy.BestOfN(ExtractEvents) # Best-of-N
dspy.ReAct(ExtractEvents) # Agentic tool use
dspy.Refine(ExtractEvents) # Self-reflection
Same signature. One line. Completely different inference architecture under the hood.
To re-implement all of those different inference strategies in LangChain or other frameworks will take… easily more than 5-10x the lines of code. (and likely bugs)
This 1-line change is one of the most powerful features of DSPy. In many projects, there are moments where 1 part of the LLM pipeline is the largest source of error. This is the closest “wave a magic wand and solve the problem” solution, allowing fast iteration with very few code changes. This is the power of DSPy signatures, which, unlike regular structured outputs in other agent frameworks, can abstract away the middleware computation.
As a more recent example, DSPy recently released dspy.RLM module for DSPy, building on very exciting recent work for Recursive Language Models (RLM) by Alex Zhang and Omar Khattab, and you can use RLMs in your codebase with a 1-line change if you’re using DSPy! (Caveat: sandboxes might be a bit more pain)
Again, a recurring theme here is that DSPy provides useful abstractions that make the code more succinct, so the developer does not need to get into the low-level details of how LLMs pass data to one another. This parallels how traditional compilers abstracted away low-level memory/register operations in assembly code, and focus on high-level variables and operations.
One might argue that agentic AI coding now makes boilerplate irrelevant. However, even if agents write 50 LOC as easily as writing 1 LOC, the “less-is-more” principle applies strongly here. Even with AI coding, the bottlenecks shift from writing code to reviewing and maintaining it. Shorter, cleaner code significantly reduces the cognitive load for engineers, making feature development and iteration faster; a pattern that shows up time and time again.
Historically, better abstractions with faster iteration speed have always taken market share over time. For example, for ML frameworks in the past, TensorFlow dominated by being first, but PyTorch won by winning over AI researchers, thanks to its dynamic computation graph, providing a nicer developer experience for the researchers. (Fun fact: a lot of parallels between dspy.Module and PyTorch’s nn.Module) And I believe the same will happen with this DSPy-style abstractions of LLM computation, with every agent framework embracing this “DSPy philosophy”.
DSPy prevents lock-in: The LLM Compiler
The 🍒cherry-on-top feature of DSPy is, in my opinion, the automatic prompt optimisation, which a) prevents LLM lock-in, b) improves the performance of LLM pipelines.
You may think: “LLM routers prevent lock-in!” - Kind of. While the model availability landscape is as competitive as ever, many strange model-specific prompts still need to be adapted for each model to achieve optimal performance. Model-specific weird prompts include:
“You are an expert tax consultant. Your role is…”
JSON prompting vs XML prompting
etc….
And these model-specific idiosyncrasies add friction to switching models, adding light lock-in.
This is where DSPy’s automatic prompt optimisation is relevant. DSPy has many analogues to a compiler: Compiles DSPy Programs -> Special prompts optimised for each model. (To clarify, you don’t need to optimise at every LLM/Agent runtime for every small change made. It just helps with squeezing performance when you’re at the optimisation phase.)
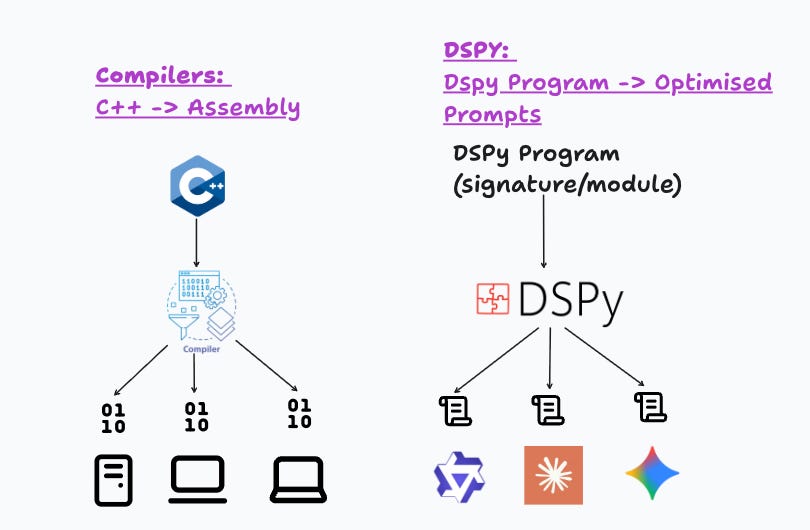
DSPy’s prompt optimisers (e.g. GEPA, a genetic algorithm to optimise prompts, although GEPA details are out of scope for this post) are similar to a compiler’s optimisers in the following sense: Write high-level logic in DSPy signatures and modules, DSPy auto-prompt optimisers write optimised model-specific prompts, and when you switch models, you just run the optimiser for the specific LLM, generating a prompt for the LLM, while your code stays the same.
In the 1940s, early programmers wrote assembly for specific machines and had to rewrite and optimise for every hardware model. Then compilers emerged, and assembly succumbed to higher abstractions (e.g. C, C++). I believe DSPy programs (signatures, modules) are a good analogue of these higher-level abstractions for LLM programs.
Similar to how the best way to achieve peak performance in computers is still to hand-write assembly code, I do believe that human experts hand-crafting prompts will be the best way to squeeze peak performance. That said, it cannot be understated that this handwriting approach should not be the default for the majority of developers. (ala Knuth: “Premature optimisation is the root of all evil.”)
Caveats: Modern LLMs are getting smarter, and the need to doweird prompting tricks has diminished a lot. However, all the value of the abstraction still remains.
This “compilation” approach with DSPy future-proofs your system because your signatures will compile to take advantage of better models as they arrive.
Conclusions
DSPy Developer Experience Enables:
Faster iteration
Get up & running fast with short code
Shorter, cleaner code: Better maintainability, less noise, more signal, faster code review
Optimise
1-line Inference strategies with dspy modules
Auto-optimisation against eval data with optimisers
Summary
DSPy enables fast iteration, with short, clean code
DSPy is like a compiler, preventing LLM lock-in
DSPy can improve LLM system accuracy with 1-line changes, enabling fast iteration & experimentation
Footnotes
One weakness of DSPy, due to its limited popularity, is its lack of native integration with popular LLM observability tools like LangFuse. I maintain a Python Template GitHub repo (github.com/Miyamura80/Python-Template) with DSPy and LangFuse integration.
Thanks to Keivan Samani and Nihir for feedback on this post!
Regarding the topic of the article, your point about DSPy as an LLM compiler is truely insightful! What if this paradigm shift becomes mainstream? Imagine how much faster we could innovate without prompt engineering minutiae bogging us down. So exciting for AI development!